" height="48.00000014038086px" id="xQ5vVHKqO" width="172.73399414062501px"/></svg>)
Consumer Goods
Optimizing Supply Chain Processes with Real-Time Analytics Platform
RUBICON Develops a Custom Real-Time Operation Analytics Supply Chain Management (SCM) Platform for a Global Client

Client quote
Their level of maturity is outstanding. They have a strict methodology for running projects, and it works absolutely smoothly. We haven’t had any hiccups. It's one of the best projects I’ve ever been involved in in my 20-year career. Overall, it’s incredible how well-organized they are as a company."
Team Lead Analytics Use Case
Overview
Effective supply chain management is vital for manufacturing and retail businesses, optimizing production and ensuring efficient delivery of products to customers. The best way to ensure a successful supply chain management process is by integrating digital technology into business operations and investing in a robust Supply Chain Management (SCM) application.
SCM applications are used for a number of processes including demand planning, supply network planning, production planning, precise scheduling, sourcing and supplier management, and analytics and logistics.
Recognizing the importance of integrating digital technology into operations, our partner, a global Chemical & Consumer Goods Company with over 100 years of history, sought to enhance their SCM process. They aimed to replace their existing off-the-shelf software solution, which was costly and lacked unified and performant access to data, with a custom Supply Chain Management (SCM) data platform.
The company partnered with RUBICON to develop a high-performing, cost-effective web platform tailored to their specific requirements. The project began with a successful proof of concept (POC), demonstrating the feasibility of the proposed solution. This achievement paved the way for the development of the first version of the SCM data platform, focusing on providing unified and performant access to data and enhancing the overall supply chain management process.
Challenges
While developing the SCM application, our team overcame the following challenges:
Replacing off-the-shelf solution that has performance and usability issues with a customizable full ownership solution
Making proof of technology choices, feasibility, and performance
Choosing the best-fit Serving and Interactive Querying Storage for a supply chain network big dataset
Creating a full-stack solution that enables near real-time querying of a supply chain dataset (40 million rows of data)
Enabling a user-friendly way to filter the supply chain with more than 40 million rows of data in the main dataset and provide performant UI visualization of the supply chain data on the world map
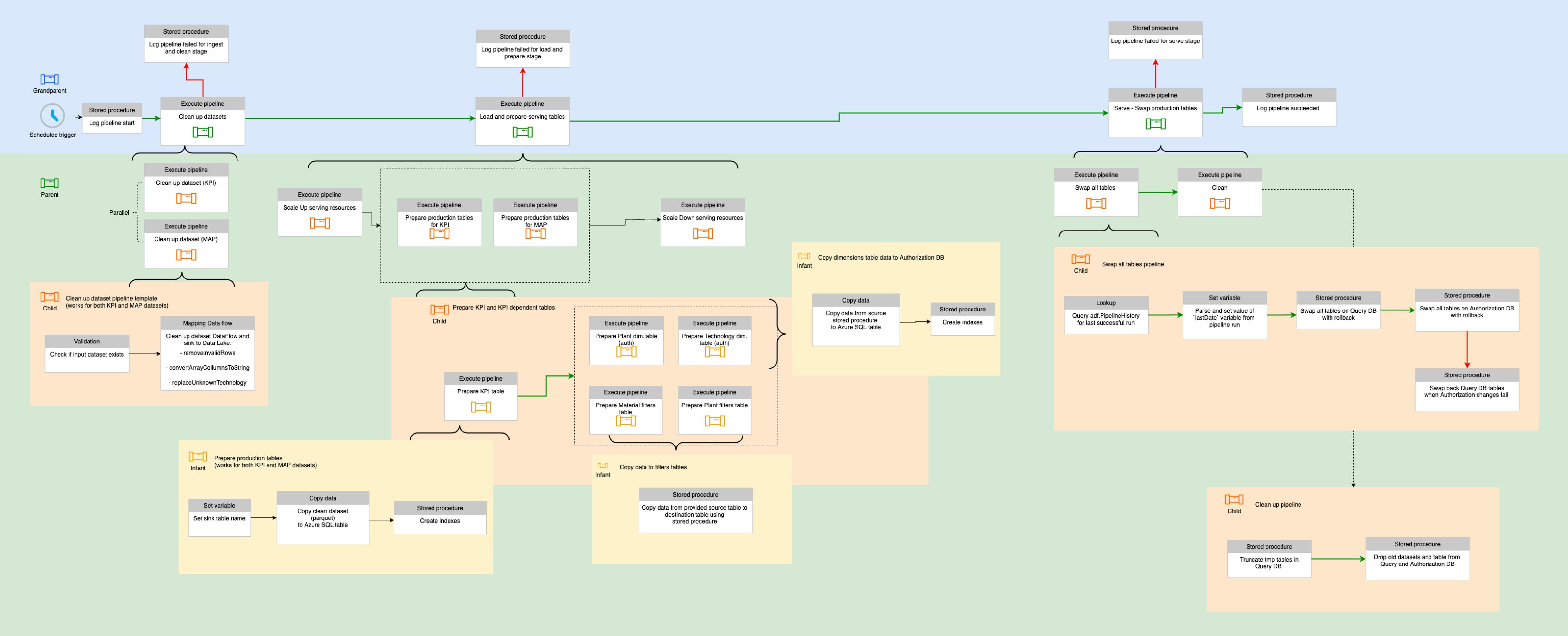
Building ETL pipelines for extracting, cleaning, transforming, and loading datasets into the Serving Storage
Creating a Custom Authorization System that integrates with other services and enables secure dimension-based access to data
Reducing cost within the selection processes by automating specific aspects of the cost calculation, a complex task requiring precise planning and execution
Implementing a cloud-native solution on Azure, ensuring secure access to relevant data, and fully automating DevOps processes
Solutions
The POC entailed building a technical proof of concept that would meet all of the client’s requirements. These included building a full-stack solution enabling near real-time querying of supply chain network datasets (40 million rows of data), capable of filtering and displaying network data on the UI map. The goal was to create a fast, efficient, and affordable data-driven platform that quickly (near real-time) queries, analyzes, and aggregates supply chain network data. The solution needed to provide better performance, flexibility, and modularity, and give the client full ownership of the product. After a successful and feasible POC, the final solution was to develop the product itself, ie. the first version of the SCM data platform.
The project officially started right at the end of POC, in August 2020. At the beginning, we organized a workshop with the client where we finally agreed on the scope of the project and the features they wanted to implement. By the end of 2020, we developed the V1.0 of the platform. The development of V1.1 started at the end of 2020 and lasted until June 2021.
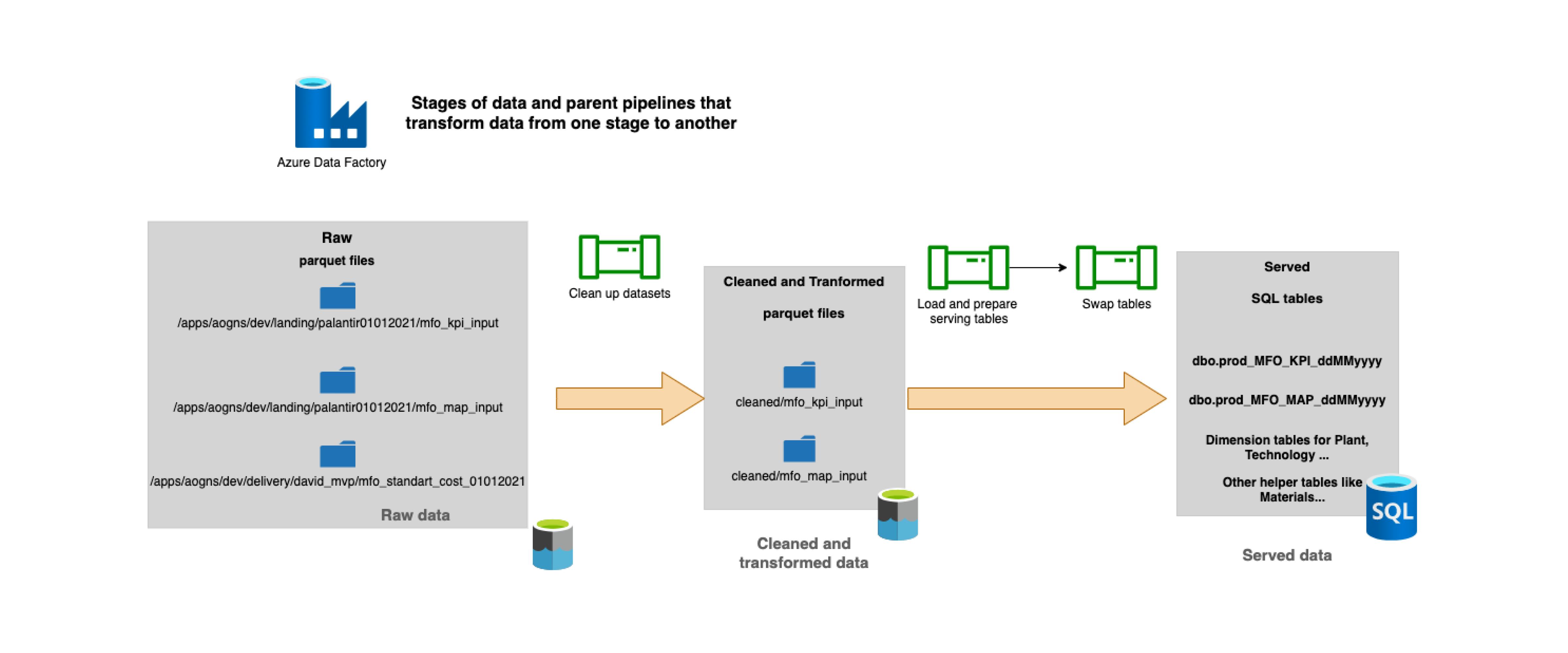
ETL data pipelines
ETL pipelines enabled a seamless transformation of datasets in the platform. This automation significantly accelerated the processes performed on the platform.
In short, ETL stands for “extract, transform, load”. These are the three interdependent processes of data integration where the data is moved from one stage to another. Once loaded into the Serving and Querying database, this data can be used for analysis, reporting, and obtaining business insights.
Working in agile
The very first thing that the team created during the POC development was a product roadmap that they would be following throughout the project development phase. Practicing the Agile methodology and working in Scrum, the team organized the project into two-week sprints. Azure DevOps was used as a key tool that helped the team keep organized and follow the process of their work.
Thanks to RUBICON’s agile approach, we successfully and on time implemented both V1.0 and V1.1. The clear and constant communication and involvement of the client as well as the swiftness of developers and their ideas contributed to the overall success of the project.
Results
In June 2021, we delivered the cost-effective and high-performing final version of the product.
Our team successfully managed to:
Implement an architecture and cloud-native solution using Azure-managed services, choosing the most suitable service for near real-time operational analytic scenarios
Improve performance by 10X and more in some cases compared to the original software, enhancing efficiency and responsiveness
Build ETL pipelines for extracting, cleaning, transforming, and loading datasets into the Serving and Querying database, streamlining data management
Deliver a cost-effective and high-performing final version of the product in June 2021, meeting the project's timeline and quality expectations.
Enhance the client's supply chain management process by providing unified and performant access to data, contributing to the overall efficiency and success of their operations
Reduce costs and increase efficiency within the selection processes by automating specific aspects of the cost calculation and enabling user-friendly filtering of the supply chain data
Position the client as a leader in their industry, showcasing their commitment to technological innovation, and providing them with full ownership and flexibility of the custom SCM data platform
Technology stack
Microsoft stack: C#, ASP. NET Core, Distributed Services Architecture, Azure Data Factory, Azure SQL, Angular, Databricks, Mapbox, AG-Grid, Git, Azure DevOps, Docker, IaaC Terraform, Terragrunt (GitOps), Azure SQL Database, Azure CosmosDB, Azure Queue Storage, Azure Blob Storage, Azure Functions, Azure Active Directory, Microsoft identity platform, Azure App Service, Azure Container Registry, Application Insights, Log Analytics
Applications and Data
Microsoft stack: C#, ASP. NET Core
- Implementing the backend API and serverless functionsDistributed Services Architecture
Azure Data Factory
- Automating ETL data processing of supply chain dataAzure SQL
- Enabling near real-time operational analytics scenarios: using column store indexes, memory-optimized tables, dynamic stored proceduresDatabricks
- PySpark application for scenario cost calculation and simulation
- Spark, PySpark, DevOps
- Azure Function to orchestrate job execution
Frontend Technologies
Angular
Modular design paired with lazy loading for fast load time
Implementation of the custom component library using core Angular features like reactive forms, content projection, and Angular templates with a focus on performance, reusability, and developer experience.
- All components apply On push change detection strategy for maximum performance
- By focusing on reusability we were able to streamline the development of the client’s other projects
- We took inspiration for component structure design from the Angular Material library to enhance developers' experienceAsync pipe subscription pattern to minimize the risk of memory leaks
Sass style preprocessor with BEM naming for scope control
Mapbox
Integration with wrapper Angular library using directives and components
Mapbox Geocoding API for forward and reverse geocoding
AG-Grid
Displaying and editing data directly from tables
Custom field types and restrictions
Exporting data from the tables
DevOps
Git
- Version control and a multi-repository project structure were used. Each component of the MFO system had its own repository and CI/CD pipelines.Azure DevOps
- The one-stop shop for all the MFO agile processes. We used it to plan, collaborate and deploy our solution.Docker
- Our solution was containerized with Docker and Docker Compose so that developers could have the whole microservice architecture up locally and with one command.IaaC Terraform, Terragrunt (GitOps)
- Provisioning the infrastructure on Azure with a combination of terraform and terragrunt. Resources were defined in terraform modules and configured with terragrunt.
Microsoft Azure Cloud
Azure SQL Database
- Storing application-related dataAzure CosmosDB
- Storing authorization system dataAzure Queue Storage
- Storing messages that are used for updating the authorization systemAzure Blob Storage
- Used by Azure Functions, for storing terraform state files and table storageAzure Functions
- Hosting the custom authorization system and orchestrating the Pyspark application job executionsAzure Active Directory, Microsoft identity platform
- Implementing single sign-on authenticationAzure App Service
- Hosting the backend APIsAzure Container Registry
- Storing container images for deploying the backend APIsApplication Insights, Log Analytics
- Monitoring the application





" height="48.00000014038086px" id="y_gzzqZQT" width="172.73500122070314px"/></svg>)
